example data tables that need to be normalized what does that mean sql
A Consummate Guide to Database Normalization in SQL
Tackle messy tables head-on with PostgreSQL.
Imagine yous've but been asked to manage your company'due south relational database system. Eager to impress, you quickly run a few initial queries to familiarize yourself with the data… simply to find the tables in organizational disarray.
You freeze. You're worried nearly the negative impact the inconsistent dependencies could have on future data manipulation queries and long-term analyses. But you lot're also unsure of what steps to take to correctly redesign the tables. And suddenly the unwelcome urge to dig through your notes from the database management form you took a lifetime agone begins to plague y'all.
Sound familiar?
Don't panic. Whether you have inherited a messy database, unintentionally synthesized one with poor integrity (whoops! 😬), or want to avert the in a higher place scenario altogether, database normalization is the solution for you lot.
What is Database Normalization?
According to the database normalization folio on Wikipedia:
"Normalization entails organizing the columns (attributes) and tables (relations) of a database to ensure that their dependencies are properly enforced by database integrity constraints."
Yikes.
Don't let these types of definitions scare you off. Translated into plain English, this simply means that normalization is the process of creating a maximally efficient relational database. Essentially, databases should be organized to decrease redundancy and avoid dependence anomalies.
In even simpler terms, your database structure should make intuitive sense. If a beau coworker is terrified of making a fatal mistake while working with a database you've created even after you explain it to them, your database probably isn't normalized.
These normalization ideals can be practical to database synthesis (creating a database from scratch) or decomposition (improving existing designs).
What are Normal Forms?
"Normalization" is a wide concept and isn't much practical employ when you're lost at sea amid a myriad of messy tables. To add concrete steps to the procedure, Edgar F. Codd detailed formal rules to follow.
Codd'south normalization guidelines accept five official normal forms, but (thankfully) the first three are usually as in-depth as you need to go. Let's briefly review these here:
Starting time Normal Form (1NF)
This initial set of rules sets the fundamental guidelines for keeping your database properly organized.
- Remove any repeating groups of data (i.e. beware of duplicative columns or rows within the same table)
- Create split up tables for each group of related data
- Each table should have a primary key (i.due east. a field that identifies each row with a non-null, unique value)
Second Normal Grade (2NF)
This side by side set of rules builds upon those outlined in 1NF.
- Meet every rule from 1NF
- Remove data that doesn't depend on the table's primary key (either move the data to the appropriate table or create a new tabular array and primary cardinal)
- Foreign keys are used to identify tabular array relationships
3rd Normal Class (3NF)
This set of rules takes those outlined in 1NF and 2NF a step further.
- See every rule from 1NF and 2NF
- Remove attributes that rely on other non-fundamental attributes (i.e. remove columns that depend on columns that aren't foreign or master keys)
Why Should You Care?
Yes, high-finish database normalization is often considered a luxury and not an absolute requirement. But even pocket-sized steps towards the correct direction tin can assistance avert slow degradation of information integrity over time.
Ensuring your database dependencies make logical sense and redundancy is minimized likewise ensures maximally insightful queries and assay.
Normalization also combats data manipulation (think DELETE, INSERT, and UPDATE) anomalies. If dependencies aren't normalized, you run the risk of assuasive for partially updated (and, therefore, partially wrong) data. Partially wrong data = partially incorrect query results down the line.
A Database Normalization Example
To fully permit these abstruse definitions sink in, permit's review each normal course with a concrete example. We'll exist focusing on decomposition throughout the examples, simply the concepts still apply to synthesis-based projects likewise.
For these examples, I personally utilized PostgreSQL (a popular, open-source relational database) and its evolution platform analogue, pgAdmin. But, again, if you prefer an alternative SQL server such every bit MySQL or Oracle, you can translate the techniques reviewed here to your platform of pick.
If you are birthday unfamiliar with these tools, delight refer to the provided sites' overview and instructional information, or Towards Data Science articles on PostgreSQL/pgAdmin such every bit this one or one.
The Data
Let's pretend you have been hired at a company that has a database with information regarding therapists located in California. For the purpose of this tutorial, I have created a mock PostgreSQL database hosted through pgAdmin with data that attempts to emulate a very small-scale slice of what a like, existent database might comprise. The database has the following tables:
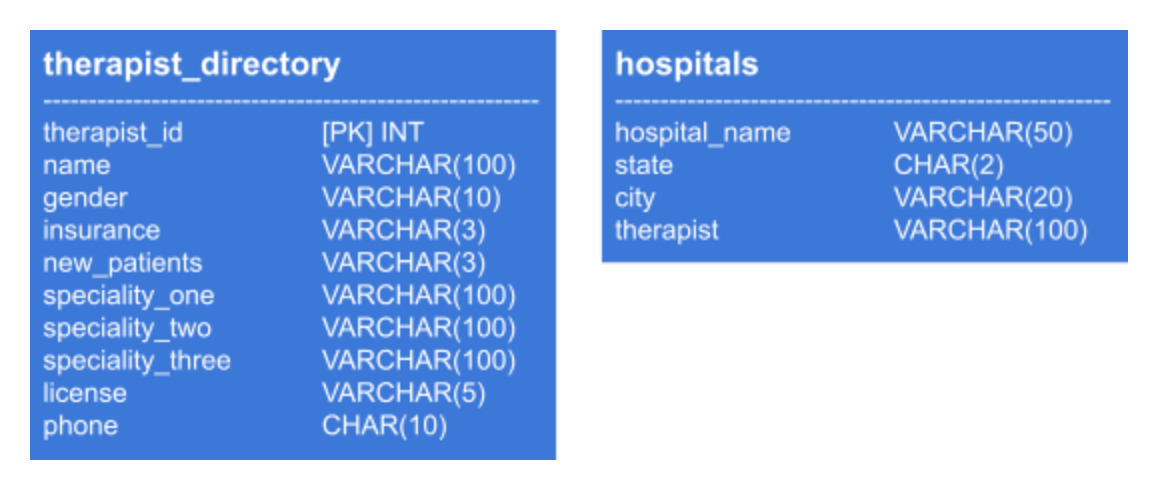
From the tables, we can meet we have an assortment of variables pertaining to the therapists, where they work, what they specialize in, and how we might contact them.
Here'south a glance into the available data itself before nosotros get started. Ever double check your values before decomposition- don't assume yous know what'south in a table by column proper noun alone.
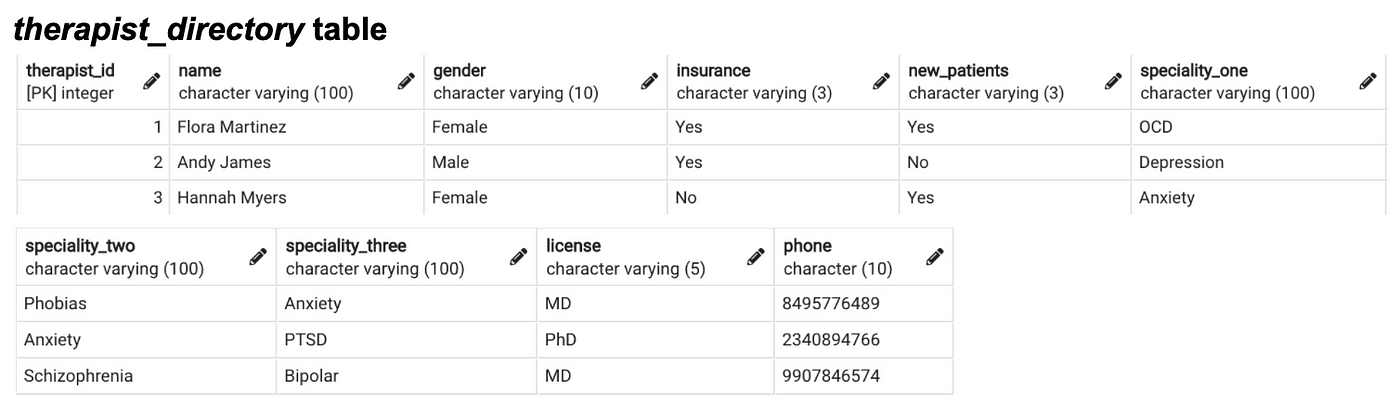
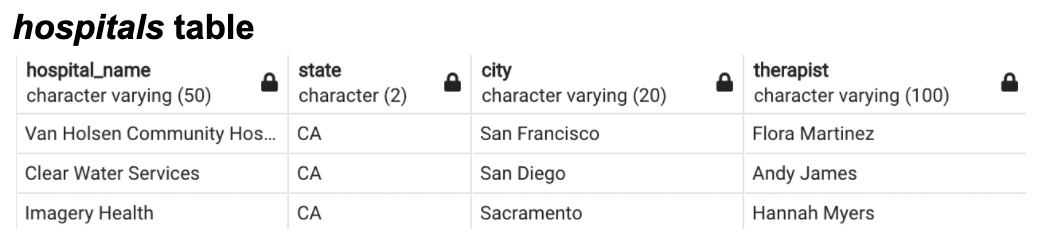
We'll continue to employ these synthetic tables throughout the tutorial. If you would like to view the original SQL syntax used to create and populate these tables, delight visit my GitHub projection repo here. Please as well keep in listen that all constructed data utilized here is for demonstrative purposes just and does non accurately represent Californian hospitals, therapist demographics, or typical dataset size (equally you lot probably already know, SQL is frequently used for big information projects, not tables with xx total rows).
An Initial Query
With the database shown above, your company would like you to run a query:
Determine the number of therapists in Northern California that specialize in mood disorders and, of these therapists, how many are currently accepting new patients.
However, afterward looking at the tables, you can tell attempting accurate queries could show to be a challenge. A relationship betwixt the 2 tables has yet to be established and there appears to be redundant information. You'll have to do some decomposition prior to running the requested query.
1NF
Recall that the start step to normalization (1NF) concerns proper row identification and grouping data correctly.
Let'southward beginning remedy the relationship between the two tables: therapist_directory (parent tabular array)and hospitals (kid tabular array). therapist_directory already has a primary central ("therapist_id"), but hospitals is lacking both primary and foreign keys. We can add an incrementally increasing primary key to hospitals with SERIAL and PRIMARY KEY specifications:
Change TABLE hospitals ADD COLUMN hospital_id Series PRIMARY KEY; Adding a foreign key volition crave pulling information from the therapist_directory table to accurately link information technology with hospitals. Although the "therapist" cavalcade in the hospitals table has each therapist's name, this isn't the ideal strange primal since, as you will see in the side by side steps, nosotros will update the corresponding "name" cavalcade in therapist_directory. Instead, let's add the therapists' IDs to hospitals for consistency's sake.
UPDATE infirmary h
Set therapist_id = td.therapist_id
FROM therapist_directory td
WHERE td.name = h.therapist; Now we can update the included "therapist_id" cavalcade in hospitals to indicate that it is a foreign key, accurately linking the tables in the database. Consequently dropping the "therapist" column from hospitals will also ensure the data in the table is relevant specifically to the therapists' places of work.
ALTER TABLE hospitals
ADD CONSTRAINT fk_therapist_directory
Strange Key (therapist_id)
REFERENCES therapist_directory(therapist_id); At present let's also address redundant information present in the tables.
After referring to the data once more, nosotros see that, in order to keep the data in its most reduced form, nosotros should dissever therapist_directory's "name" column into outset and concluding names columns with the use of SUBSTRING().
/* make new last_name column */
Alter Tabular array therapist_directory ADD COLUMN last_name VARCHAR(30); /* add last name values to last_name */
UPDATE therapist_directory
SET last_name =
SUBSTRING(name, POSITION(' ' IN name)+ane, LENGTH(proper name)); /* update proper noun cavalcade to first_name */
Alter Table therapist_directory
RENAME Column proper noun TO first_name; /* remove last name substring from first_name */
UPDATE therapist_directory
Set first_name =
SUBSTRING(first_name, 1, POSITION(' ' IN first_name)-1);
In that location are also repeating groups of data in the therapist_directory table ("speciality_one", "speciality_two" and "speciality_three"). We'll move these variables to their own tabular array. Don't forget to add a primary and foreign central to the new table! (Run into GitHub hither for full SQL utilized).
CREATE TABLE IF NOT EXISTS specialties(
specialties_key series PRIMARY KEY,
speciality_one VARCHAR(100),
speciality_two VARCHAR(100),
speciality_three VARCHAR(100),
therapist_id INTEGER,
CONSTRAINT fk_therapist
FOREIGN Primal(therapist_id)
REFERENCES therapist_directory(therapist_id)); Allow's have a look at the database schema at present.
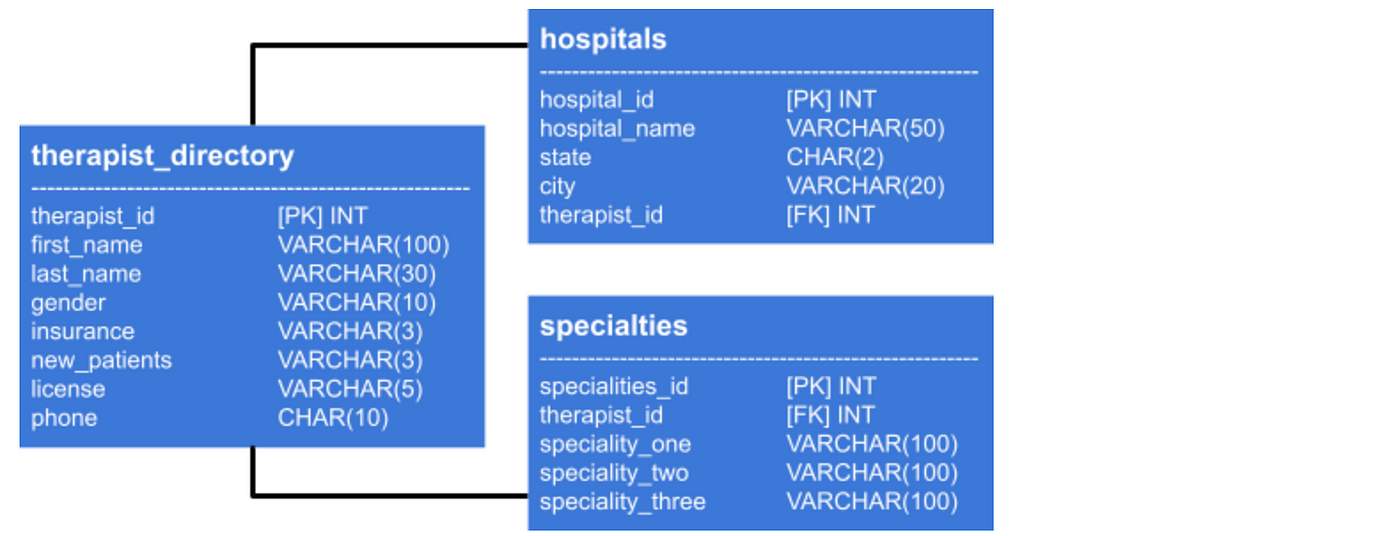
Everything looks good then far. Fourth dimension to move onto 2NF.
2NF
Remember that 2nd normal form involves removing data unrelated to the primary key and establishing foreign keys to fortify table relationships.
Since all of our tables currently have foreign keys (hurrah!), we can focus on identifying unrelated information.
Nosotros have three columns in therapist_directory that don't match up well with the "therapist_id" primary key: insurance, new_patients, and phone. "insurance" and "new_patients" don't identify who each therapist is. Rather, each points to visit specifications to consider when choosing a therapist.
With this in mind, let's move these two variables to their own table called visit_specifications. Nosotros can do then by once more utilizing the CREATE TABLE syntax. And, remember, as long equally the tables are continued with a one-to-one relationship, it's okay if a column doubles equally the principal and the strange key.
CREATE Tabular array IF NOT EXISTS visit_specifications(
therapist_id INTEGER Chief KEY,
insurance VARCHAR(3) CHECK(insurance IN ('Yes', 'No')),
new_patients VARCHAR(iii) CHECK(insurance IN ('Yes', 'No')),
CONSTRAINT fk_visits
FOREIGN Key(therapist_id)
REFERENCES therapist_directory(therapist_id)); Bully, at present nosotros but take one unrelated column in therapist_directory left: phone. Looking closely, nosotros can meet the numbers listed are actually the hospitals' telephone numbers rather than each therapist's personal contact info.
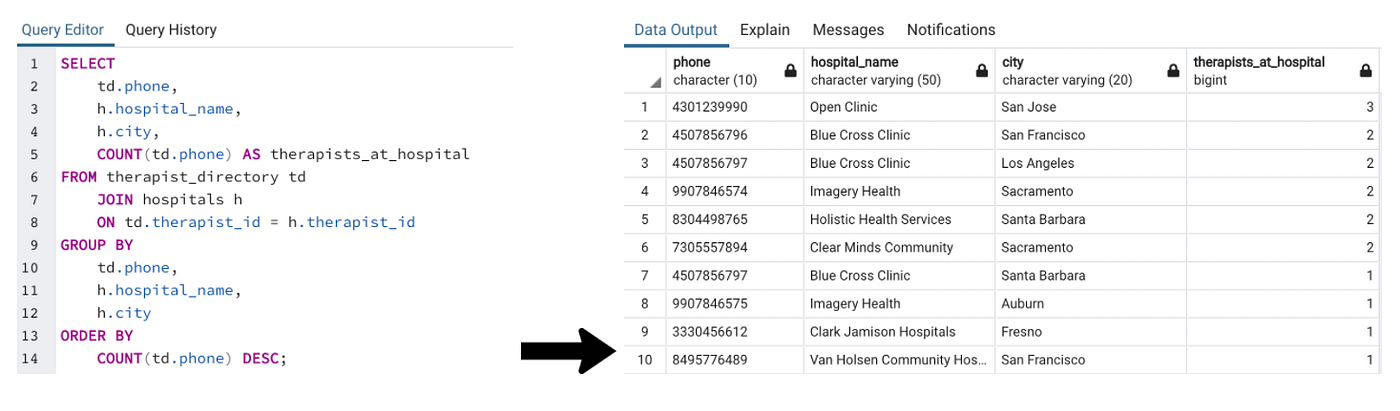
We could go alee and add together the phone numbers to the more than advisable hospitals table, but this modification would be in violation of 3NF! Allow'due south move onto third normal form to full detail why this is the example.
3NF
Recall that third normal form involves removing transitively dependent columns.
…What does that really mean? 🤨
Allow's walk step-by-pace with the "phone" column instance to make sense of this requirement.
Every bit mentioned, we could add the "telephone" column to the hospitals table to better match the "hospital_id" chief primal. However, the phone number values would then depend on both "hospital_id" and the city that the infirmary is in. Let'south have another await at the information returned from our previous query:
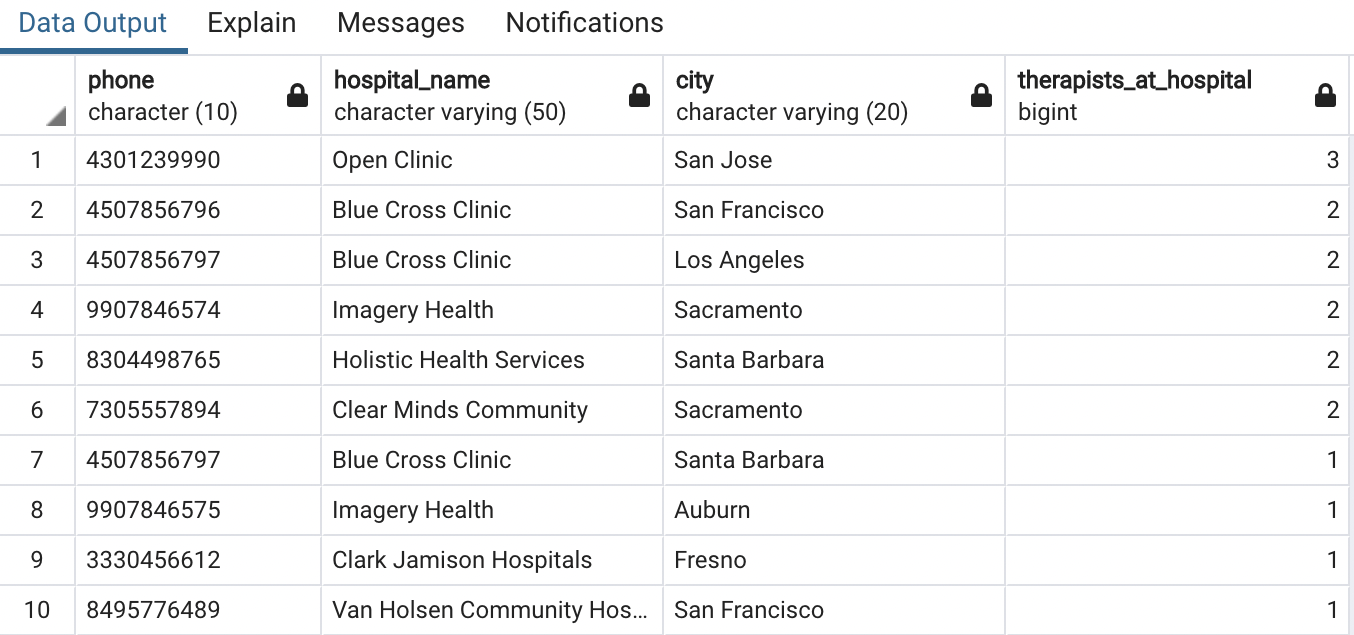
Nosotros tin clearly see that therapists who work at the same hospital in the same city all have the same phone number listed (for instance, in that location are two therapists who work at Blue Cross Clinic in San Francisco), but therapists who work at the same infirmary in varying locations have different phone numbers (at that place are two other therapists who besides work at Blueish Cross Clinic but, because they are located in Los Angeles, they have a different phone number than the 2 San Francisco-based Blue Cantankerous Dispensary therapists).
This ways that phone numbers depend on both the hospital (main cardinal) and the city the hospital is located in. Putting the "telephone" values into their own table rather than the hospitals table safeguards against accidentally changing a therapist'southward city without too changing the phone number.
This is the ground of transitive dependence: column values modify based on the master central and other columns likewise in the table.
To circumvent this breach of information integrity, nosotros can create 3 tables: one to constitute a key for each location-specific infirmary, one for phone numbers according to hospital id, and one for each therapist's respective hospital id. The terminal database schema would be as follows (once more, check out the provided GitHub page here for consummate SQL queries):

Awesome, at present our columns depend but on their respective main key! This concludes our normalization steps 🥳
The Initial Query Revisited
At present that the database meets 1NF, 2NF, and 3NF standards, you can revisit the query your visitor requested. Here's a refresher just in example:
Decide the number of therapists in Northern California that specialize in mood disorders and, of these therapists, how many are currently accepting new patients.
Assuming that mood disorders include "Anxiety", "Depression", and "Bipolar", you tin use the following query without creeping doubts about data integrity:
SELECT
sub.new_patients,
COUNT(therapist_id) AS norcal_therapists
FROM
(SELECT s.therapist_id, s.speciality_one, due south.speciality_two, s.speciality_three, td.new_patients
FROM specialties due south
JOIN therapist_directory td ON s.therapist_id = td.therapist_id
JOIN therapist_location tl ON td.therapist_id = tl.therapist_id
JOIN locations 50 ON tl.hospital_id = l.hospital_id
WHERE fifty.city ~ '(San Francisco|Oakland|San Jose|Sacramento|Auburn)') sub
WHERE
speciality_one ~ '(Anxiety|Low|Bipolar)'
OR speciality_two ~ '(Anxiety|Depression|Bipolar)'
OR speciality_three ~ '(Anxiety|Low|Bipolar)'
GROUP By sub.new_patients; 
According to the results, at that place are 11 therapists in Northern California that specialize in mood disorders and, of these 11, nine are currently accepting new patients!
Beyond general assay like this, a normalized database with non-transitively dependent columns also allows us to consummate information manipulation queries with confidence. If your company had instead asked yous to modify the city (but not the hospital) a therapist works in, you lot could easily do so with the use of a unmarried UPDATE statement without worrying about accidentally declining to simultaneously update the phone number.
UPDATE
therapist_location
Prepare
hospital_id = (SELECT hospital_id
FROM locations
WHERE hospital_name = 'Open Dispensary'
AND city = 'San Jose')
WHERE
therapist_id = fifteen; The to a higher place query changes Sid Michael'due south (therapist_id = 15) infirmary location to San Jose rather than Oakland. Because her hospital id is now up-to-date in the therapist_location tabular array, we don't demand to alter Sid's contact info by hand with another UPDATE query. Instead, Sid's contact info is automatically updated according to her new hospital id. We tin double-check this with a JOIN statement.
SELECT
td.first_name,
td.last_name,
l.hospital_name,
fifty.city pn.phone_number
FROM
therapist_directory td
JOIN
therapist_location tl
ON td.therapist_id = tl.therapist_id
JOIN
locations l
ON 50.hospital_id = tl.hospital_id
JOIN
phone_numbers pn
ON tl.hospital_id = pn.hospital_id
WHERE
td.therapist_id = 15; 
A Brief Closing Message
Decomposing a database can be equally uncomplicated every bit 1(NF), two(NF), three(NF)! For more than insight into the mock "Northern_California_Therapists" database and the private SQL queries synthesized for this commodity, bank check out my related GitHub repository here.
Happy normalizing! 🤖
geisslerilthaddly.blogspot.com
Source: https://towardsdatascience.com/a-complete-guide-to-database-normalization-in-sql-6b16544deb0
0 Response to "example data tables that need to be normalized what does that mean sql"
Post a Comment